
I Trained a Model Using Karpathy's Autoresearch — Here's How It Works
22 experiments, 64% improvement, zero manual tuning — all while I slept


Karpathy has broken the internet again with Autoresearch. He has a knack for distilling complex problems to their essence (read microgpt) and this is no exception.
Autoresearch is an autonomous AI agent designed to iteratively improve LLM training code without human supervision. It means the capability to optimize and model on any dataset and improve it on certain metrics is no longer bound by manual intervention or ML expertise. The core idea of Autoresearch is elegant and crisp. You give an AI agent a training script and a metric. It edits the code, runs a short experiment, checks if the metric improved, keeps or discards the change, and repeats. After an overnight run of ~100 experiments, you wake up to a model with dramatically better performance — discovered entirely by the agent.
In a way, Karpathy delegated the most expensive part of ML research to a team of agents, reduced the cost massively, and open-sourced it for experimentation. I don’t see a reason why this won’t be adopted at every scale. Why wouldn’t small, specialised models emerge from a single GPU or Apple chip — trained on niche datasets, solving personalised problems that massive general-purpose LLMs can’t touch?
To experiment with Autoresearch, I trained a model from scratch on my M4 MacBook Air. I set up the code based on Karpathy’s repository and prepared the initial training script. The dataset I used was TinyStories — a collection of ~2.7 million simple children’s stories generated by GPT-4, totalling around 673MB of clean text data. After running ~20 experiments, the results were striking.
The baseline model (val_bpb: 2.5471) with the prompt “Once upon a time” produced complete gibberish:
“Once upon a time stay!.Heithuboming named ySoon... traffic. turned an369. dead Sally humane...”

By the final experiment, the best model (val_bpb: 0.9145) generated coherent children’s stories:
“Once upon a time, there was a little boy named Bob. Bob loved to run and play with his friends in his lazy house. One day, he went to the park with his friends. They would play games and had a great day at the park...”

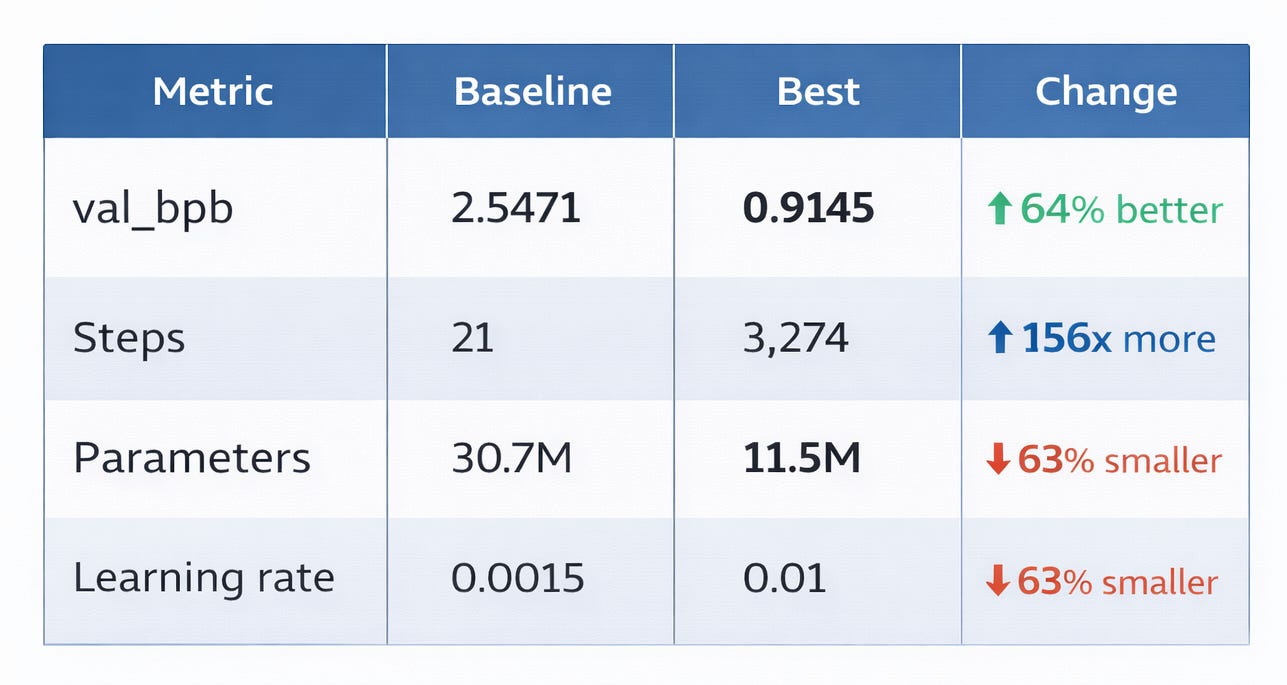
That’s a 64% improvement in the core metric — achieved entirely by the AI agent experimenting with architectures and hyperparameters while I slept. The agent discovered that a smaller model (11.5M parameters vs 30.7M baseline) trained for more steps (3,274 vs 21) dramatically outperforms a larger model that barely trains within the 5-minute budget.
Now, the technical details will follow. But pause for a moment to grasp what just happened: seamless, autonomous training on a dataset — no manual tuning, no ML expertise. This opens up real opportunities viz. specialised small-scale models that are cheaper to run and effective on domain-specific data. Evolving overnight on ideas you define. So let’s look at why training your own model is suddenly a viable option.
First things first - Why would you or anyone train a model?
The moat is real in creating small, specialized models trained on your dataset, solving your niche tasks at a fraction of the cost.
Think about it , you don’t need a $20/month API subscription to Opus or GPT-4 for every problem. Many tasks are repetitive, numerical, and domain-specific — exactly where small custom models shine. A pricing model for your e-commerce store. A demand forecaster for your inventory. A sentiment scorer for your industry’s jargon. A fund selection model trained on 10 years of NAV data. These don’t need reasoning or creativity — they need fast, cheap, accurate predictions at scale.
The economics are stark. Calling an LLM API costs ₹0.50–2 per request. At 100,000 predictions per day for a small medium enterprise trying to solve a local problem, that’s ₹15–60 lakh per month. Instead compare it to a small custom model which runs locally on precisely the problem that you need to be solved, costs essentially nothing per inference, responds in milliseconds, and keeps your data private. No rate limits. No API outages. No sending your transaction history to a third party.
Small models also compound well. Training runs finish in minutes, and improvements transfer when you scale up. The role of humans in handling and improving the models changes. Instead of directly tuning models, you spin up a swarm of agents that collaborate to experiment on smaller models. These agents explore variations in training code, architecture, and hyperparameters, and the most promising ideas are gradually promoted to larger scales. Humans can step in at the edges to guide or evaluate, but much of the exploration is automated.
This is fundamentally different from prompt optimizers, which only tune prompts on top of frozen models. Systems like Autoresearch go deeper. They modify the model itself by changing the training pipeline, architecture, and hyperparameters, allowing the system to discover improvements that prompts alone could never reach.
This opens up real possibilities at a one person/small team granular level to add value for.
Delving into the details - How does Autoresearch work
As mentioned, Autoresearch is an autonomous AI research agent that iteratively improves LLM training code without human supervision. The system has a minimal 3-file architecture. That’s it. Three files that fit in a single LLM context window:
prepare.py — One-time setup. Downloads the dataset and trains a tokenizer. Run once, never touched again.
train.py — The GPT model and training loop. This is what the AI agent modifies during experiments.
program.md — Instructions for the AI agent. Tells it what to optimize, what metrics matter, and what constraints to follow.
The experiment loop is deceptively simple:
AI reads program.md to understand the rules
AI modifies train.py (changes learning rate, layer count, embedding size, etc.)
Runs a 5-minute training experiment
Checks if val_bpb improved (lower is better)
Keeps the change if it helped, discards if it didn’t
Repeats
Each experiment is exactly 5 minutes — TIME_BUDGET = 300 seconds. This constraint is critical. It ensures fair comparison across experiments. If one run took 5 minutes and another took 30, you couldn’t compare their metrics meaningfully. The fixed budget forces the agent to find configurations that train efficiently within the time limit. These can be the decision to reduce the batch size or increasing the training steps, all shall be based on the level playing field of an experiment run for 300 seconds.
What is val_bpb?
val_bpb stands for validation bits per byte. It measures how well the model predicts the next token on held-out validation data. Lower is better. Unlike raw loss values, val_bpb is vocabulary-size independent — meaning you can fairly compare models with different tokenizer configurations. It’s the north star metric the agent optimizes against.
What can the AI agent modify?
The agent has free rein over train.py within defined boundaries:
Hyperparameters: Learning rate, batch size, weight decay, dropout
Architecture: Number of layers, attention heads, embedding dimensions
Training dynamics: Optimizers, learning rate schedulers, gradient clipping
Activation functions: GELU, ReLU, SiLU
What it cannot modify: prepare.py (data and tokenizer must stay stable) and TIME_BUDGET (must remain 5 minutes for fair comparison).
Details on Improving the TinyStories Model — A Small-Scale Model for Generating Stories
Let me walk you through exactly what I did, what happened, and what the agent discovered.
The Dataset: TinyStories
I used TinyStories — a dataset created by Microsoft Research containing approximately 2.7 million simple children’s stories generated by GPT-4. The total size is around 673MB of clean text data. Why this dataset? It’s simple vocabulary, consistent narrative structure, and easy to evaluate qualitatively. You can read the generated output and immediately tell if the model is working — is it gibberish or an actual story!
The dataset is hosted on HuggingFace (karpathy/tinystories-gpt4-clean) and downloads as a single parquet file — tinystories_gpt4_clean.parquet, approximately 673MB containing all 2.7 million stories. The prepare.py script handles this automatically — it downloads the data and trains a BPE tokenizer on the text. (A tokenizer splits text into tokens that the model can process. BPE — Byte Pair Encoding — learns to merge frequently occurring character pairs, so common words become single tokens while rare words split into subwords. This keeps vocabulary small while handling any text, including unseen words.) Unlike some larger datasets that split into multiple shards, TinyStories comes as one file, which simplifies the setup.
The Hardware: M4 MacBook Air
I ran the entire experiment on an Apple M4 MacBook Air. This immediately hit a constraint. The default batch size of 32 caused an out-of-memory error — the attention mechanism uses O(seq_len²) memory, and with a sequence length of 2048, memory fills up fast. I had to reduce BATCH_SIZE to 4 to fit within available GPU memory. This actually became interesting — it meant each experiment could complete more training steps (processing data in smaller chunks), which turned out to be a key factor in the results.
Setting Up the Experiment
The setup was straightforward:
Install dependencies: pip install -r requirements.txt (torch, pyarrow, requests, tiktoken)
Prepare data and tokenizer: python prepare.py — downloads TinyStories, trains the tokenizer, saves everything to ~/.cache/autoresearch/
Run baseline: python train.py — runs the first 5-minute experiment and establishes the baseline metric
Start the AI agent with program.md instructions — the agent takes over from here
Once the agent started, I stepped away. It ran experiments autonomously, modifying train.py, running 5-minute training cycles, checking val_bpb, and iterating.
The Baseline: Where We Started
The first experiment established the baseline with default hyperparameters:
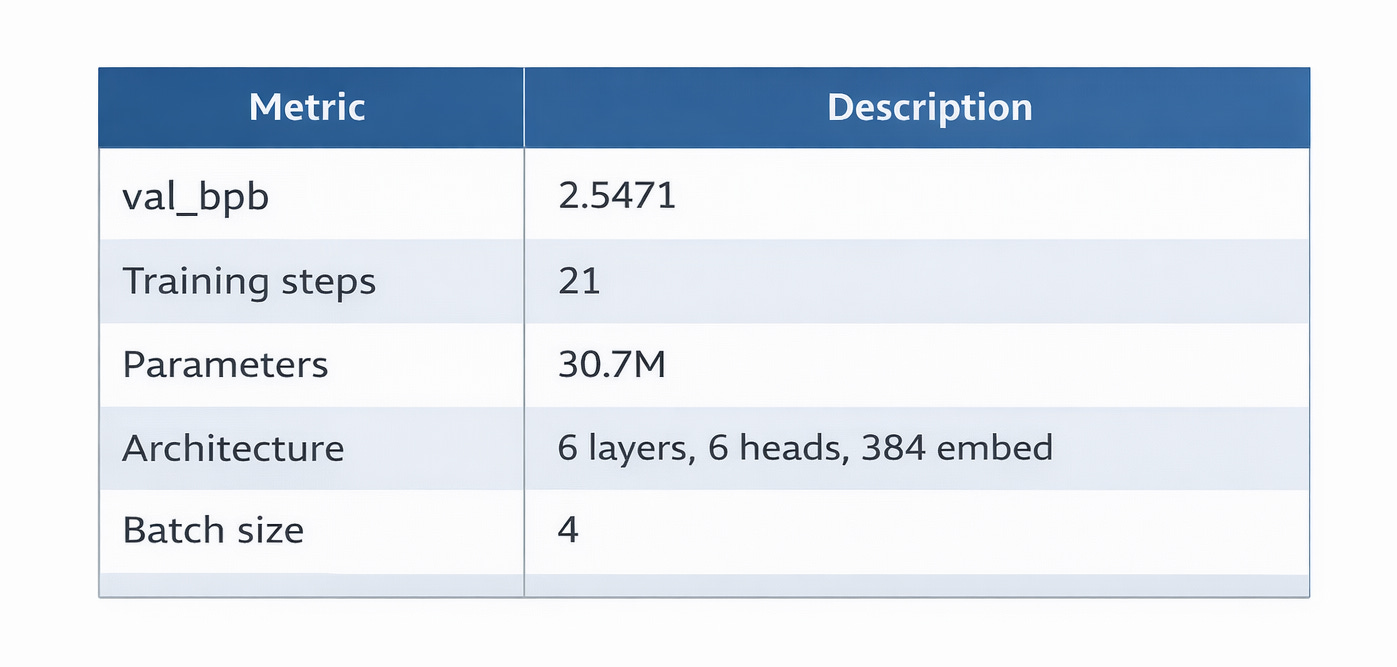
Only 21 training steps in 5 minutes. The model was too large for the hardware and time budget — it spent most of the time on forward and backward passes through a 30-million parameter network, barely getting any gradient updates.
The output reflected this. When prompted with “Once upon a time”, the baseline model produced:
“Once upon a time stay!.Heithuboming named ySoon... traffic. turned an369. dead Sally humane...”
Complete gibberish. Random punctuation, nonsensical fragments, numbers appearing out of nowhere. The model had learned essentially nothing in 21 steps.
The Experiments: What the Agent Tried
Over the course of 22 experiments, the agent systematically explored the hyperparameter space. Here’s what happened:
Experiment 2 — The First Breakthrough
The agent’s first move was aggressive: shrink the model. It reduced to 4 layers, 4 heads, 256 embedding dimensions, increased the learning rate to 0.001, and disabled dropout entirely.
Result: val_bpb dropped from 2.5471 to 1.4563 — a 43% improvement. Training steps jumped from 21 to 276. The smaller model trained 13x more steps in the same time budget.
Experiments 3-9 — Optimizing Further
The agent continued refining. It tweaked the architecture, adjusted learning rates, experimented with gradient clipping. By Experiment 9, it had achieved val_bpb of 0.9818 with 2,554 training steps.
Experiment 10-11 — Batch Size Exploration
The agent tried increasing batch size to 8, then 16. Batch size 8 worked slightly better (0.9606). Batch size 16 was worse (0.9761) — fewer total steps despite larger batches.
Experiment 12 — The Architecture Breakthrough
Here’s where things got interesting. The agent tried an even smaller embedding dimension: 4 layers, 3 heads, 192 embed. This reduced parameters to 11.5M (from the baseline’s 30.7M) and allowed 3,094 training steps.
Result: val_bpb of 0.9548. The agent had discovered that on this hardware, a smaller model training for more steps beats a larger model that barely trains.
Experiments 13-17 — Testing Boundaries
The agent tested the limits. Experiment 13 went too small (4/2/128, only 7.2M parameters) — val_bpb worsened to 1.0033. Underfitting. Experiment 14 tried more layers (6/3/192) — also worse. Experiment 17 tried batch_size=16 again — still bad.
Experiments 18-22 — Fine-Tuning the Sweet Spot
The agent zeroed in on the winning configuration (4/3/192) and experimented with learning rate and weight decay. It found that LR=0.0015 and weight_decay=0.01 worked better than the defaults.
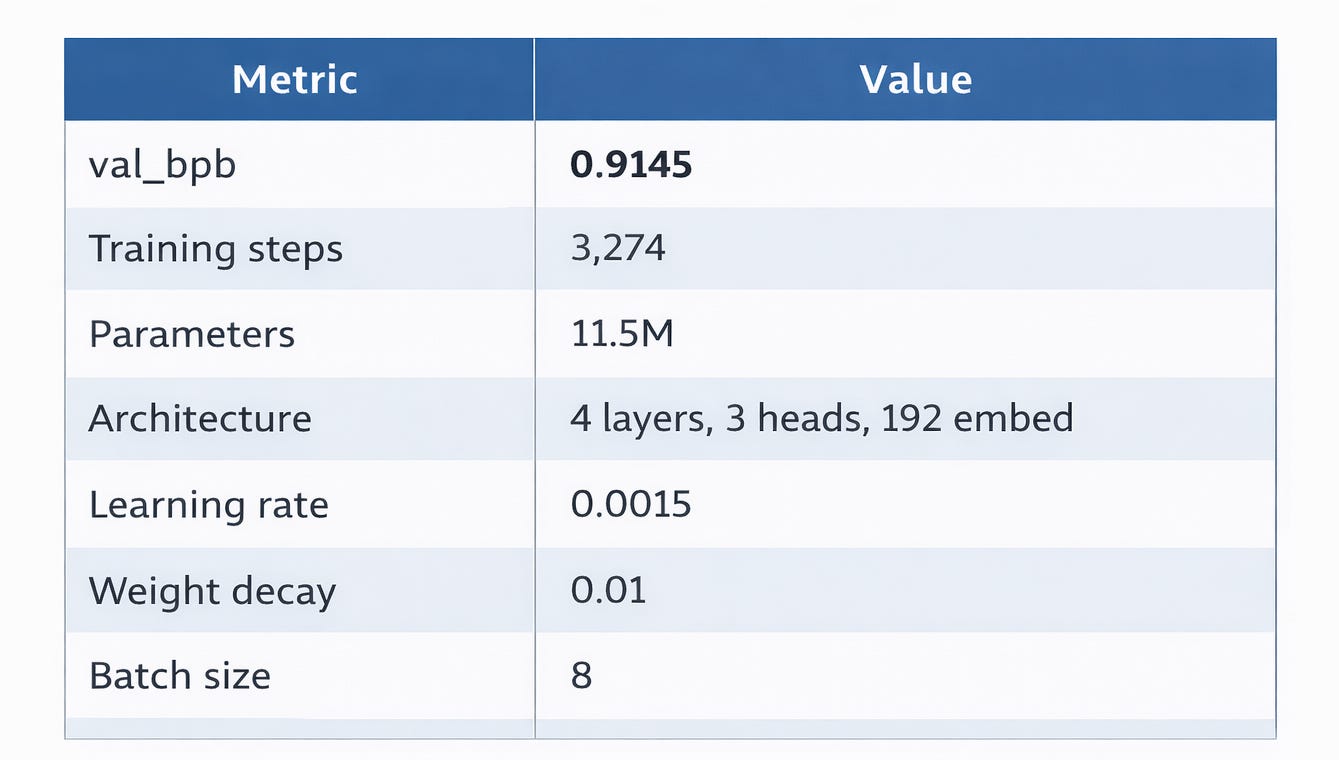
Experiment 22 — The Best Model
The final breakthrough:
What Failed — The Negative Results
Equally important is what didn’t work:
Batch size 16 — Fewer steps completed, worse results. Batch size 8 was the sweet spot.
Embedding 128 — Too small. Model couldn’t capture enough information. Underfitting.
6 layers — Too slow on this hardware. Fewer training steps, worse metric.
Weight decay 0 — Slight degradation. Some regularization helped.
Learning rate 0.002 — Too high. Training became unstable.
3 layers — Not enough capacity. 4 layers was the minimum needed.
The Final Comparison
The best model’s output with the same prompt:
“Once upon a time, there was a little boy named Bob. Bob loved to run and play with his friends in his lazy house. One day, he went to the park with his friends. They would play games and had a great day at the park. At the park, Bob saw a big hill. He wanted to take the top of it...”
Named characters. Coherent setting. Narrative progression. Actual story structure. From gibberish to this — discovered entirely by an AI agent running experiments while I slept.
The Key Insight
The agent discovered something that challenges conventional ML intuition: when training time is fixed, smaller models win. A 30M parameter model sounds impressive, but if it only completes 21 gradient updates, it learns nothing. An 11.5M parameter model completing 3,274 updates learns dramatically more.
This has real implications for anyone training models on consumer hardware. Don’t default to the largest model that fits in memory. Find the model size that maximizes training steps within your time budget. The agent figured this out through pure empirical search — no human needed to intuit it.
Wrapping Up
Running this experiment was genuinely enriching — there’s something oddly satisfying about waking up to a model that improved itself while you were dreaming about, well, models improving themselves.
But here’s the bigger picture. Frontier models in their agentic forms are already delving into autoresearch. Claude writing code, running experiments, evaluating results, iterating. And once agents get good at training smaller agents, the snowball starts rolling. Small-scale models for niche tasks — pricing, forecasting, domain-specific language — will become commoditised. Not “cheap” as an afterthought, but cheap as the default.
My view? We’re entering an era where the moat isn’t “we have ML engineers” — it’s “we have the data.” The training loop is getting automated. The architecture search is getting automated. What remains is the dataset and the problem definition. That’s where humans stay relevant. For now.
Also, I trained a children’s story generator on a MacBook while eating dinner. If that’s not the future, I don’t know what is.
---
🔗 While you are here
I’m building a repository of hands-on AI agent experiments — if you’re learning to build with LLMs and agents, this might save you hours.
https://github.com/prod-blip/aicookbook
⭐ Star the repo if you find it useful!
—-